I continue to explore different techniques of displaying images in Windows Phone and this time I will show some possible implementations of fetching them from the web using the HTTP protocol.
Classic implementation:
public static void GethttpImage1(string urlImage, Action<BitmapImage> action)
{
var request = (HttpWebRequest)WebRequest.Create(urlImage);
request.BeginGetResponse(result =>
{
using (var sr = request.EndGetResponse(result))
{
Deployment.Current.Dispatcher.BeginInvoke(() =>
{
var image = new BitmapImage();
image.SetSource(sr.GetResponseStream());
if (action != null)
action(image);
sr.Close();
});
}
}
}
urlImage is a string representation of the url of the image : example : http://dev.bratched.fr/download/testimage1.png
This method uses the WebRequest class and reads the response as a Stream using request.EndGetResponse.
The
Deployment.Current.Dispatcher.BeginInvoke(() =>
call is very important as it allows us to use the BitmapImage on the main UI thread even when the callback is invoked on a background thread.
The method will invoke the action and pass the retrieved image to this action as parameter.
It can be invoked like this in order to set a property of type BitmapImage:
HttpImageService.GethttpImage1("http://dev.bratched.fr/download/testimage1.png", b =>
{
Image = b;
});
Implementation with async/await:
The “Microsoft Async” allows to use the async/await pattern in the standard Windows Phone methods.
This package adds some extension methods to the standard WebRequest class returning Task<BitmapImage>
using (WebResponse response = await request.GetResponseAsync())
Replaces the following elements:
request.BeginGetResponse(result =>
{
using (var sr = request.EndGetResponse(result))
{
The function returns directly a Task<BitmapImage> instead of passing an action as parameter
public static async Task<BitmapImage> GethttpImage2(string urlImage)
{
try
{
var request = (HttpWebRequest)WebRequest.Create(urlImage);
using (WebResponse response = await request.GetResponseAsync())
{
BitmapImage image = null;
DispatcherSynchronizationContext dsc = new DispatcherSynchronizationContext(Deployment.Current.Dispatcher);
await Task.Factory.StartNew(() =>
{
dsc.Send(_ =>
{
image = new BitmapImage();
image.SetSource(response.GetResponseStream());
}, null);
});
return image;
}
}
catch (Exception)
{
return null;
}
}
Remark :
DispatcherSynchronizationContext dsc = new DispatcherSynchronizationContext(Deployment.Current.Dispatcher);
await Task.Factory.StartNew(() =>
{
dsc.Send(_ =>
{
replaces
Deployment.Current.Dispatcher.BeginInvoke(() =>
Here we still need to marshal the call on the main Thread to allow using the returned BitmapImage and bind it on the UI.
The async/await pattern illustrated here allows better management of the threads as it relies on the TPL. Vous pouvez la remplacer sans soucis par l’ancien code.
Here’s how you could call the function: (Image is a property of type BitmapImage)
Image = await HttpImageService.GethttpImage2("http://dev.bratched.fr/download/testimage1.png");
HttpClient
The “Microsoft HTTP Client Libraries” NuGet needs to be installed in order to be able to use the HttpClient class. The advantage of this class is that it allows to use the same syntax as we would in a Windows 8 application.
Important remark: it’s necessary to use a buffer instead of a Stream because
- BitmapImage needs to be used on the main Thread
- The Main thread cannot be used in AsyncStream
public static async Task<BitmapImage> GethttpImage3(string urlImage)
{
try
{
HttpClient httpClient = new HttpClient() { MaxResponseContentBufferSize = 100000000 };
var ImageData = await httpClient.GetByteArrayAsync(urlImage);
{
using (var s = new MemoryStream(ImageData))
{
BitmapImage image = null;
DispatcherSynchronizationContext dsc = new DispatcherSynchronizationContext(Deployment.Current.Dispatcher);
await Task.Factory.StartNew(() =>
{
dsc.Send(_ =>
{
image = new BitmapImage();
image.SetSource(s);
}, null);
});
return image;
}
}
}
catch
{
return null;
}
}
This function can be called the same way as before:
Image = await HttpImageService.GethttpImage3("http://dev.bratched.fr/download/testimage1.png");
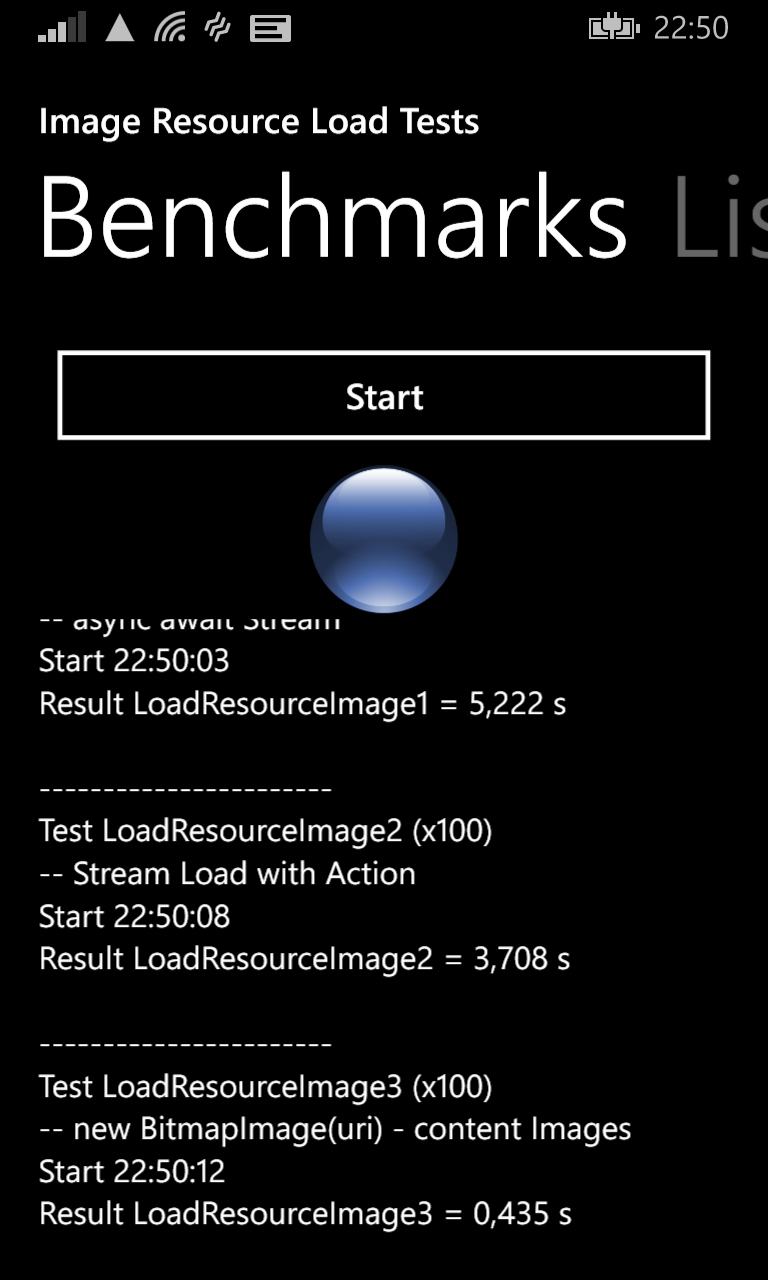
Performance tests
The 3 methods can be used but which one performs better when loading multiple images?
I have adapted the previous program from Performance tests of static images to
- Display the 3 methods in the lists
- Benchmark by loading 10 times the big png image (400K 1000×1000) from the previous article
I have also added the MemoryCounter from Coding4Fun to follow the memory usage.
Here are the results from a WiFi network (average from 20 passes).
- Method 1 : HttpRequest/Response with Action callback : 6 sec
- Method 2 : Async HttpRequest/Response : 9 sec
- Method 3 : HttpClient : 8,5 sec
During the tests I have also inverted the order of passes to avoid influencing the results.
La consultation des listes donne un réel aperçu des 3 différentes méthodes.
C’est encore une fois la méthode “classique” avec HttpRequest qui donne le meilleur résultat.
Le système d’Action permet d’éviter l’attente de la fin du traitement du thread pour interroger le réseau et permet ainsi une meilleure parallélisassions des tâches.


{kind=link}
{kind=link}